
TensorFlow概念介绍-Graph

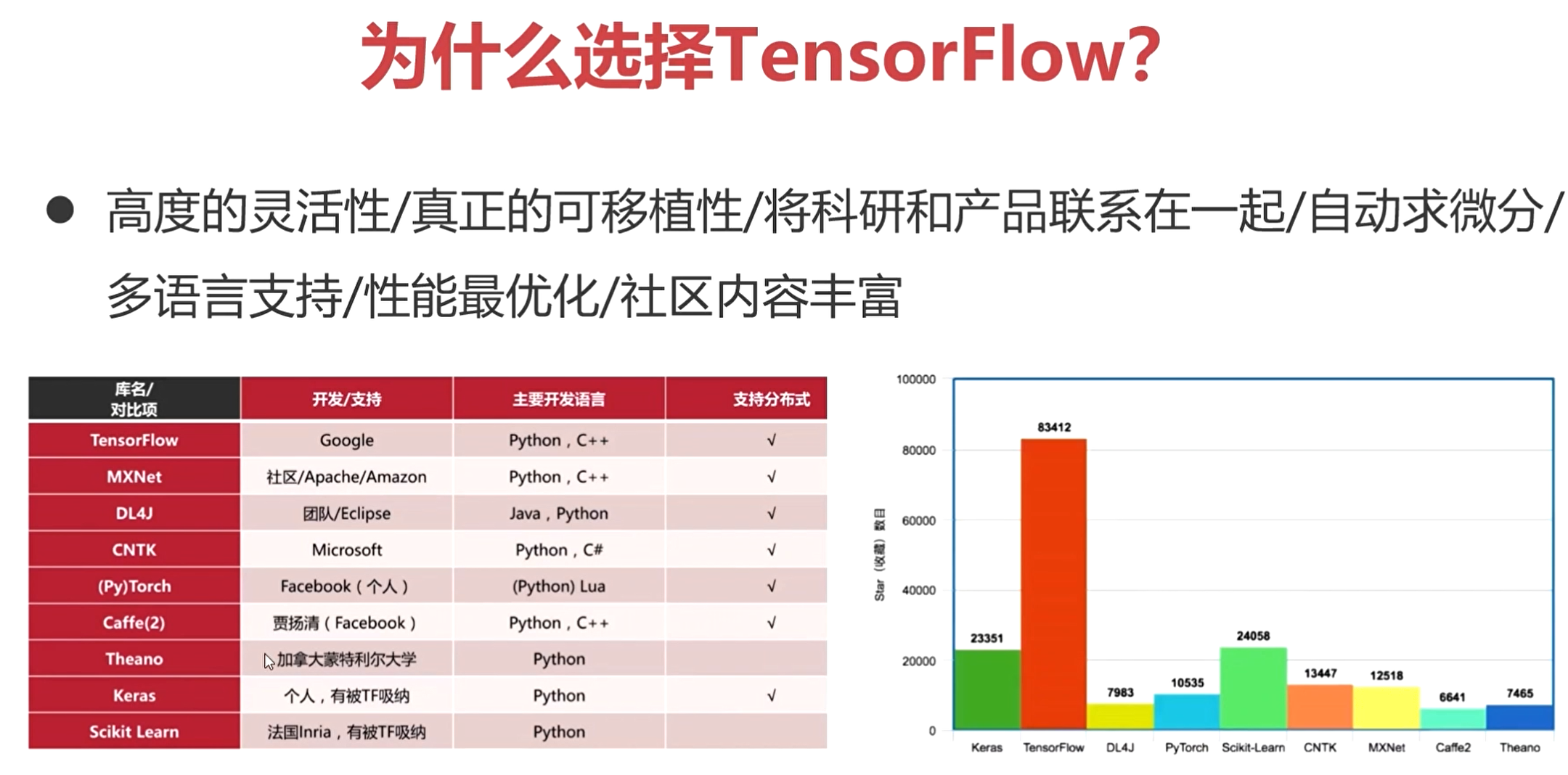
TensorFlow:Google开源的基于数据流图的科学计算库,适用于机器学习、深度学习等人工智能领域。
TensorFlow的源码是开源的,可以在github上进行下载。
安装可以直接通过pip直接安装,也可以把源码下载到本地自己进行编译。
然后TF中提供了很多模型,包括计算机视觉和自然语言处理的,在搭建模型的时候可以直接调用这里面的model。
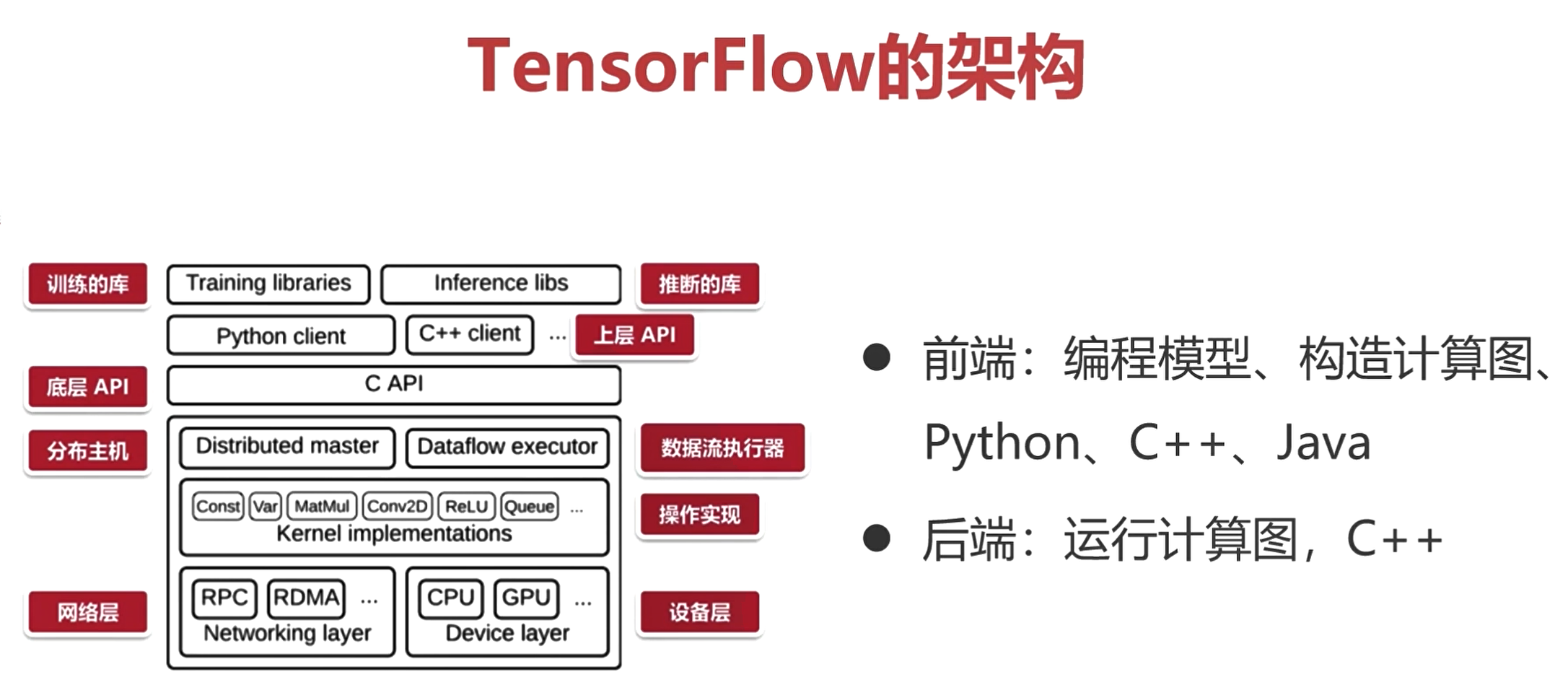
- 前端:编程模型、构造计算图、Python、Cpp、Java
网络也被称为计算图。
通过构造这样的一个图结构,并定好数据流向,来完成整个推理运算。
- 后端:运行计算图,C++
前端使用Python搭建网络模型,构造出来的计算图是不会运算的。前端搭建好计算图,并给定数据,后端再经过运算,得到输出。
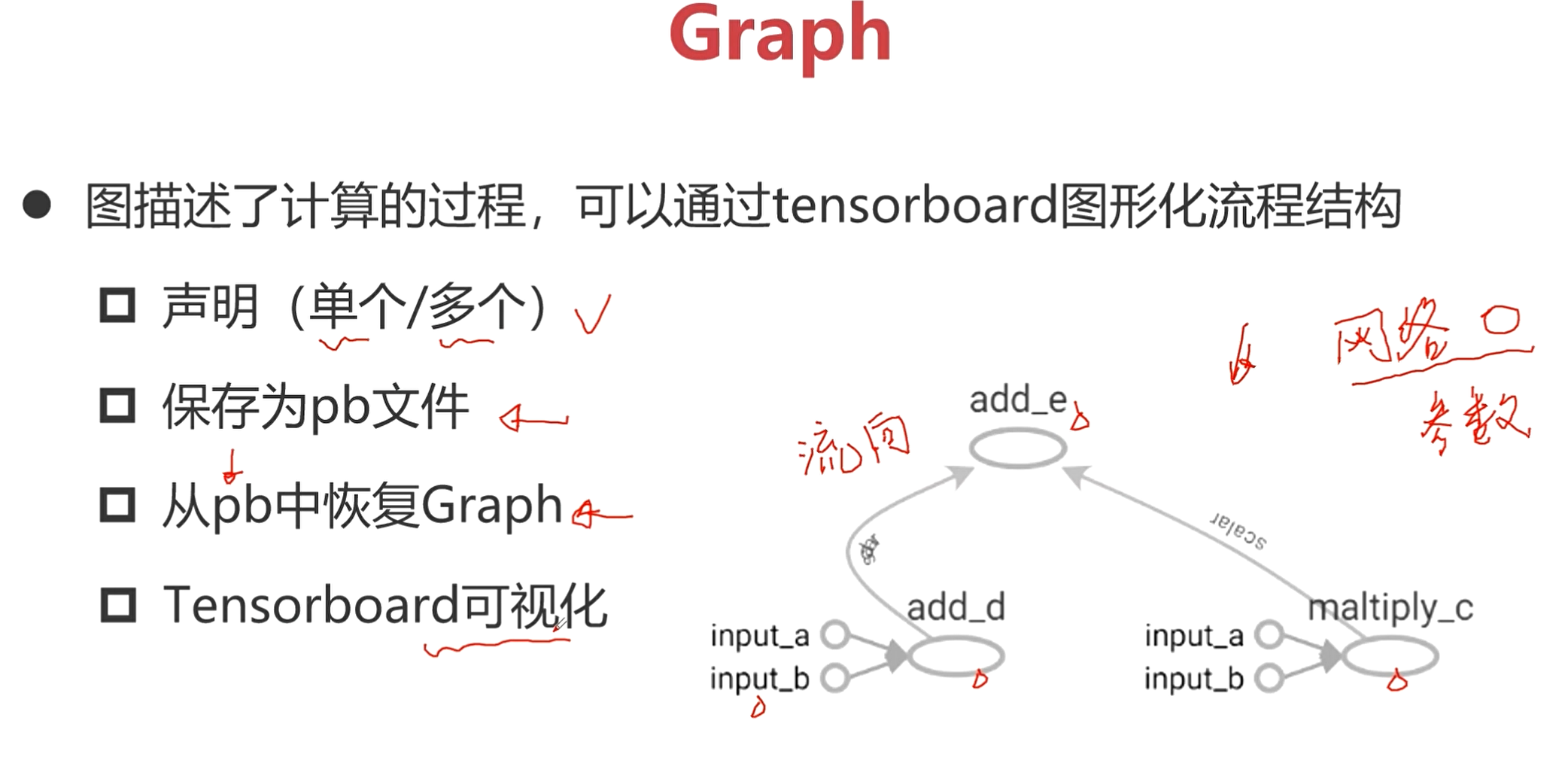
Graph:描述了整个计算过程。
- 声明(单个/多个)
一个图表示一个网络,如果需要用到多个网络来解决一个任务,那就需要声明多个图,也就是多个Graph。
- 保存为pb文件
pb文件包括了网络的结构和网络的参数。
-
从pb中恢复Graph
-
Tensorboard可视化
Graph是在前端来完成的,并且可以通过tf进行可视化展示。
上图是一个图形化的结果。



Session-Tensor-Operation-Feed-Fetch介绍

Session
- Graph必须在Session的上下文中执行
- Session将Graph的op分发到诸如CPU或GPU之类的设备上运行
Graph <=> Session <=> 后端
Session相当于是Graph和后端的一个沟通的桥梁。


注入机制: 实际上就是Session具体完成计算图的过程,也是在注入机制中完成了前端和后端这个桥梁的作用。



Tensor
- 在tf中,所有在节点之间传递的数据都为Tensor对象
- N维数组,图像:((batch*height*width*channel))

上图是tensor常用的定义方式,重点掌握前三种。
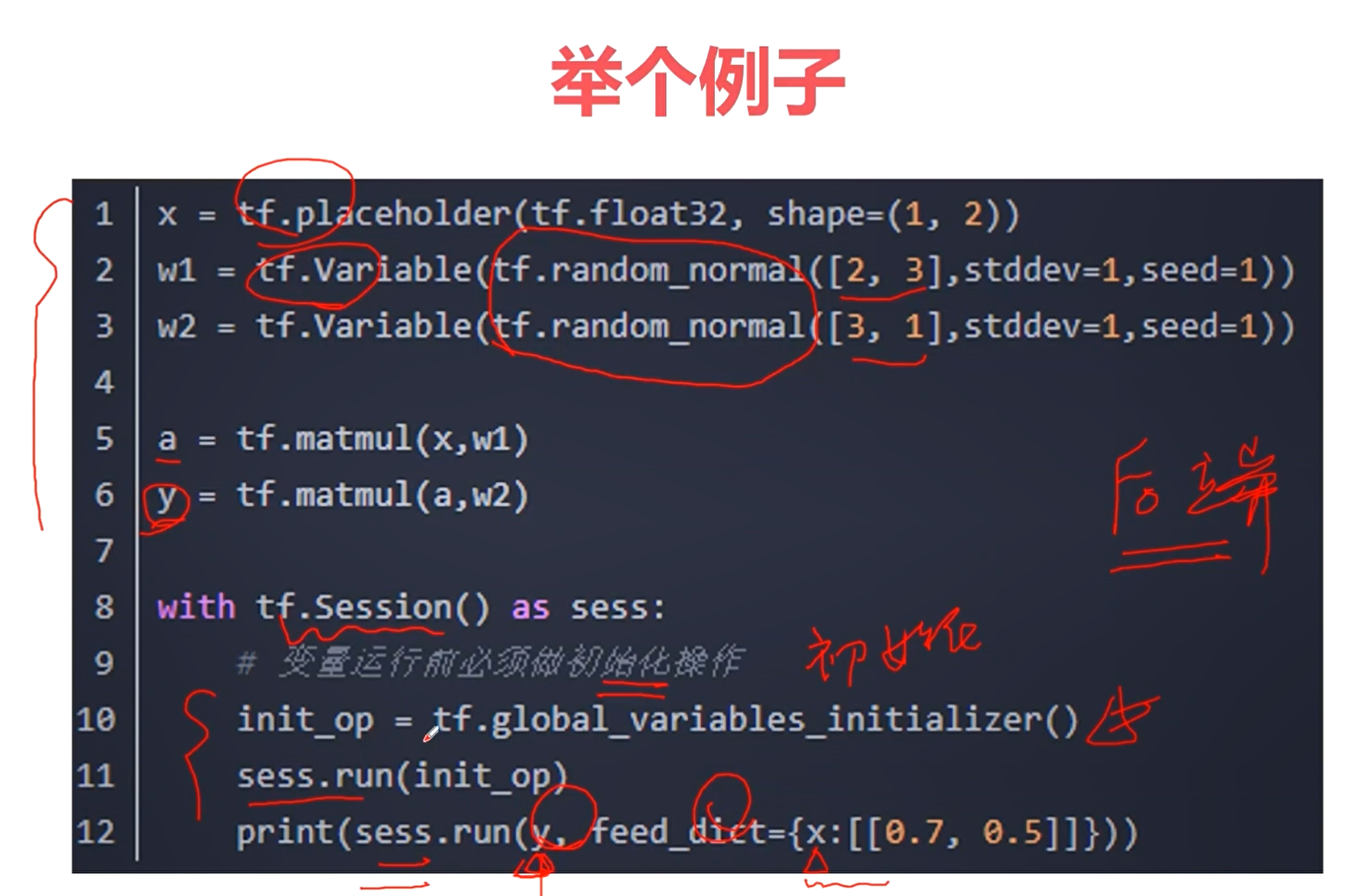
tf.constant() # 常量
tf.Variable() # 变量
tr.placeholder() # 占位符

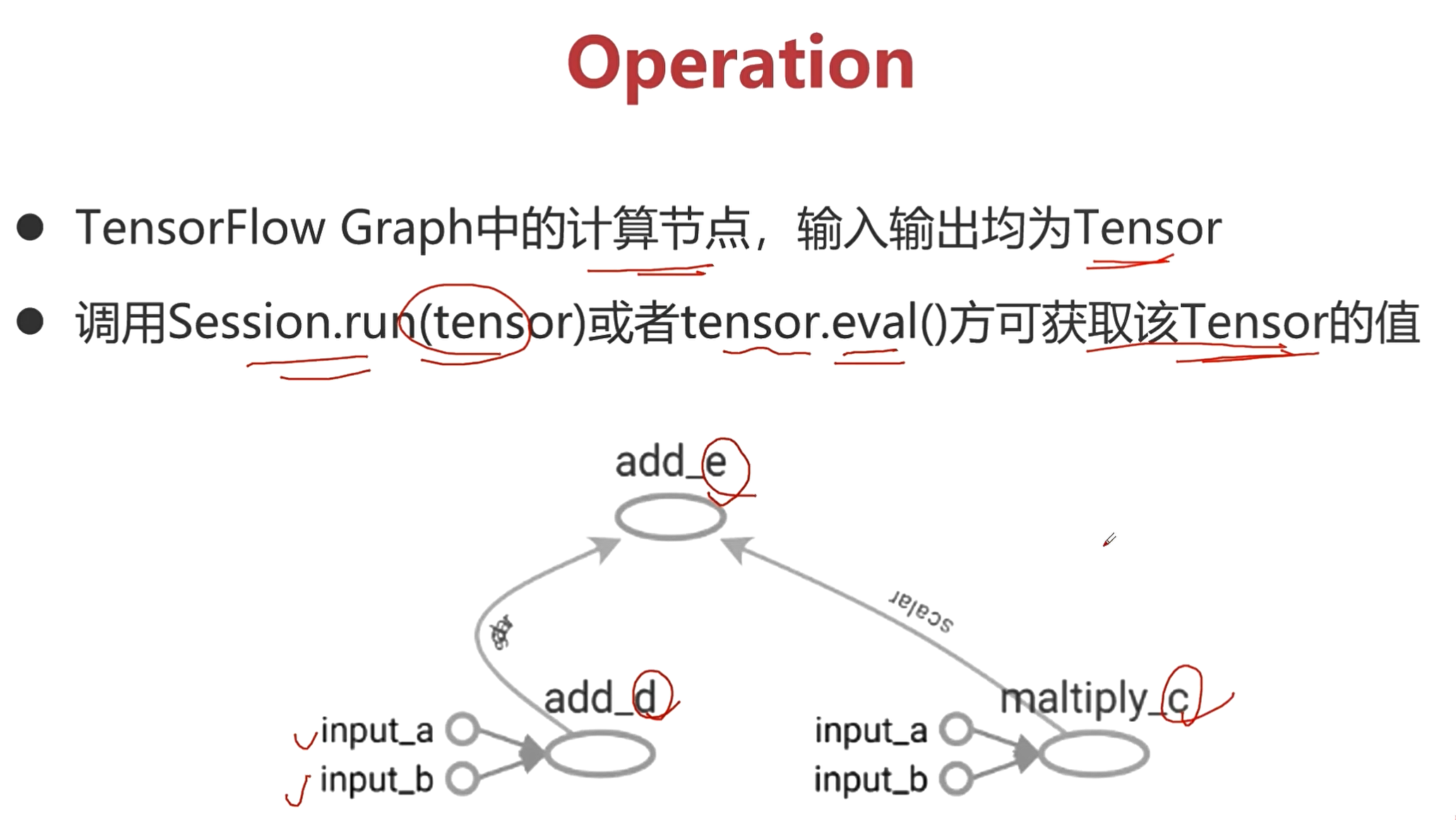
Operation(op)
- tf Graph中的计算节点,输入输出均为Tensor
- 调用Session.run(tensor)或者tensor.eval()方可获取该Tensor的值
上图中的两个add,一个maltiply都是op。
具体计算图的op(操作)在哪里完成,可以通过Session来指定完成这些op的设备资源。

Feed:通过feed为计算图注入值
Feed为Tensor完成具体值的注入,这里注入的值通常是那些占位符。
占位符是在构造计算图时,那些没有办法确定的Tensor。

Fetch: 使用Fetch获取计算结果
TensorFlow中核心API接口

上面是常用的op操作。

tf.nn 是常用的网络搭建API。

tf.train 定义了很多和优化相关的一些函数。


TFRecord: tf提供了TFRcord的格式来统一存储数据
TFRecord将图像数据和标签放在一起的二进制文件(protocol buffer),能更好的利用内存,实现快速的复制、移动、读取、存储。



TensorFlow数据读取机制与API方法
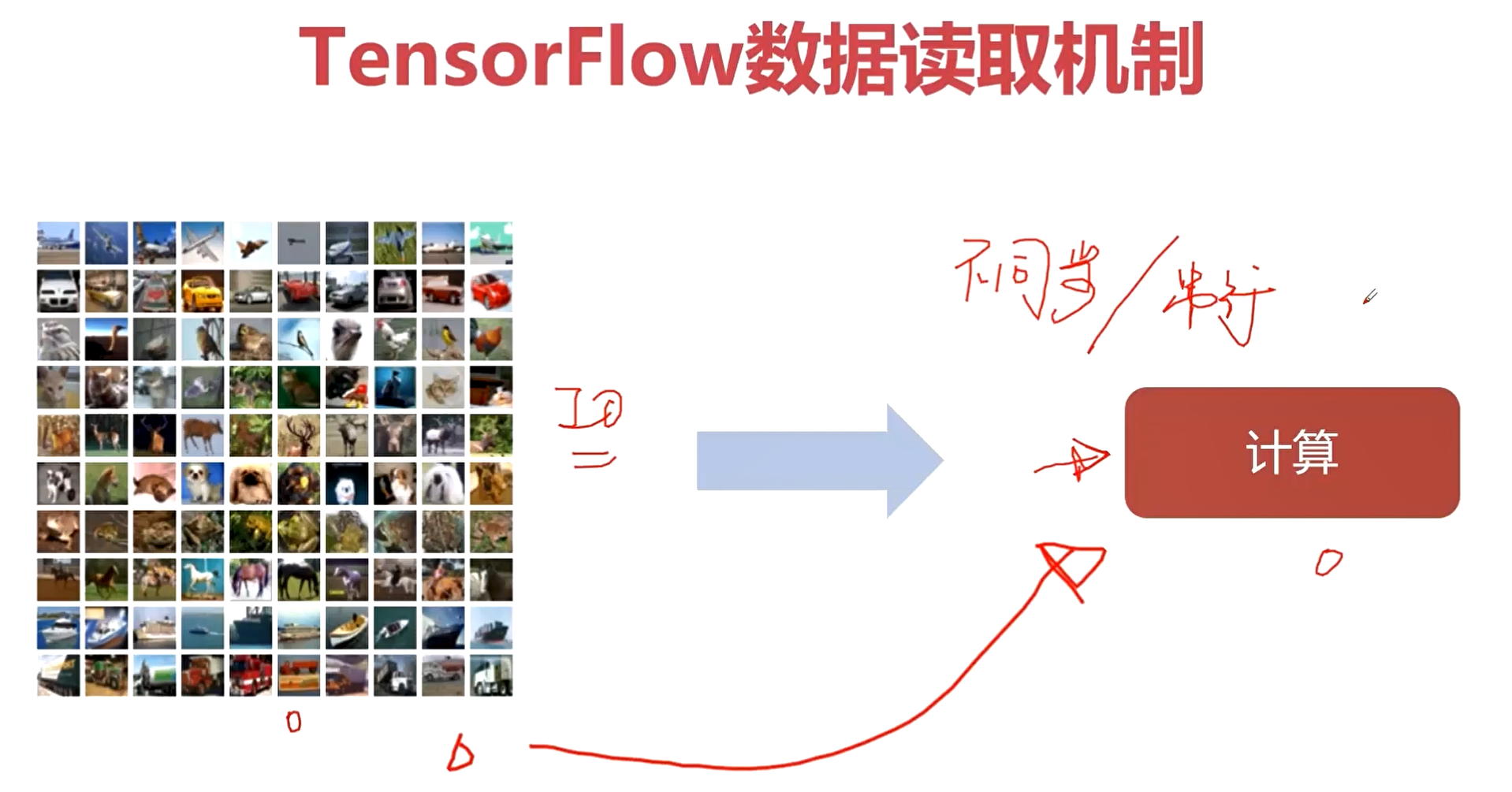
如果直接从磁盘读取数据,那么IO的等待时间会造成计算资源的浪费。
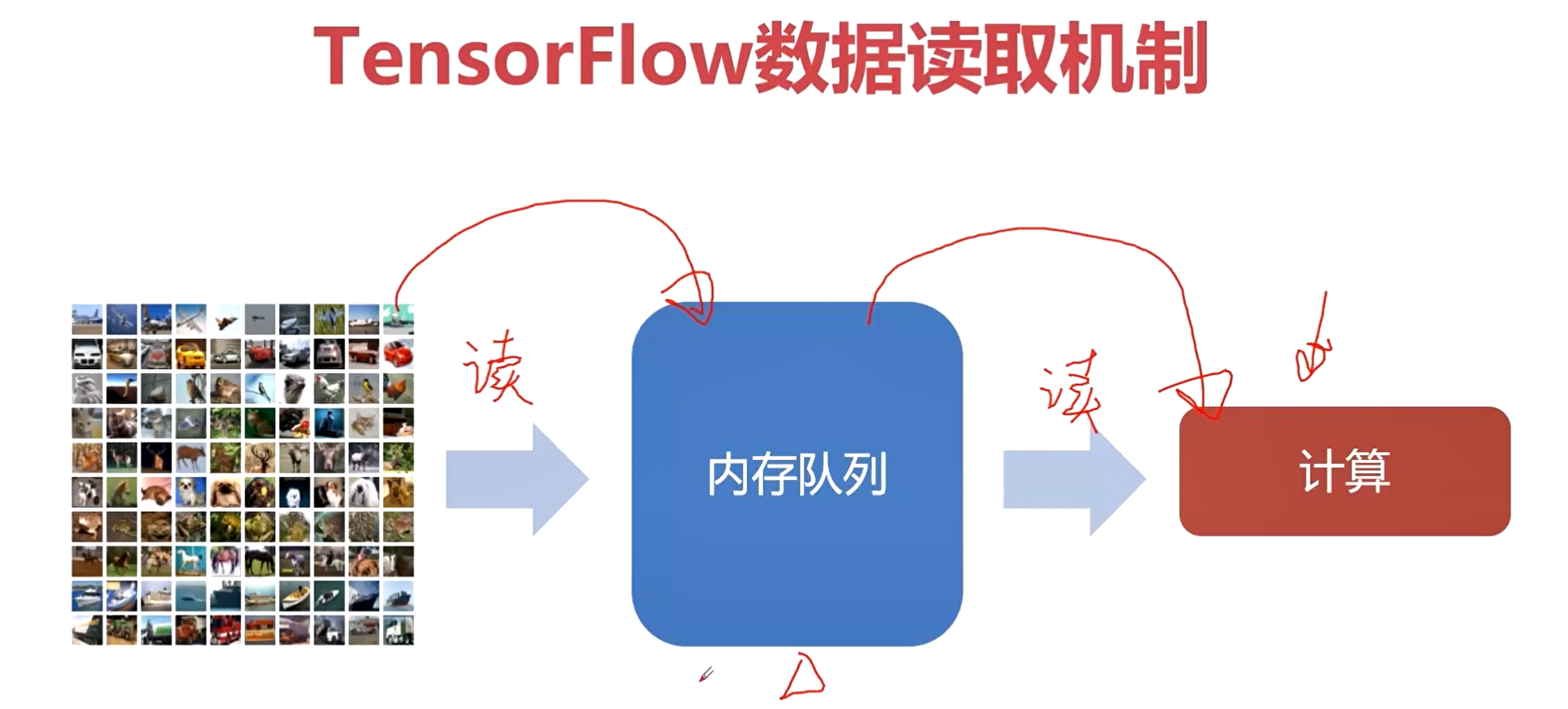
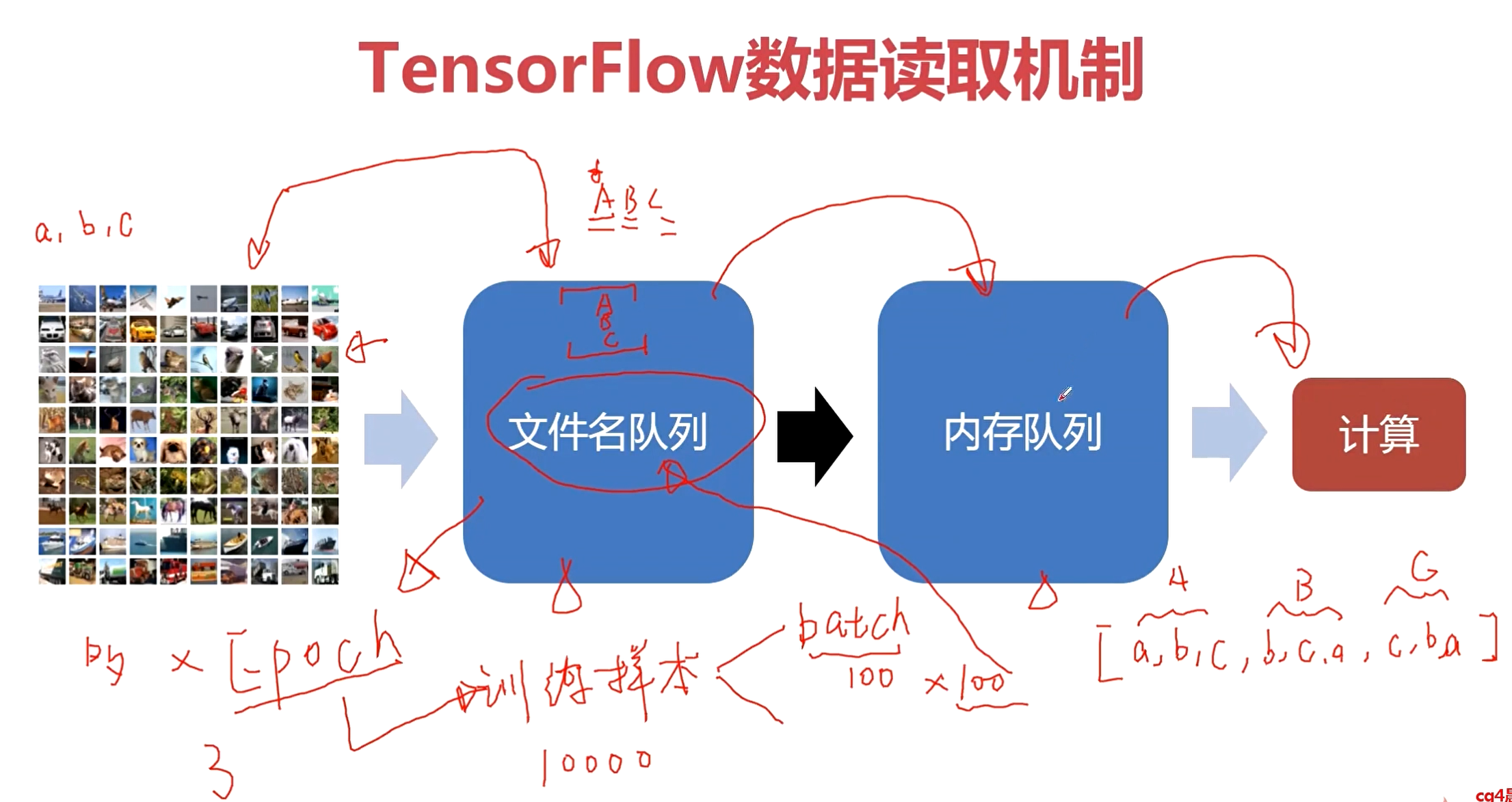
文件名队列有什么用呢?这里就涉及到我们模型训练的一个概念——Epoch。
训练样本是分为一个一个batch的,意思就是每次从训练样本中取出一部分样本,用这个一部分样本来对网络参数进行调整,进行模型的训练。
假如训练样本有10000个,batch的数量为100,那么一个Epoch就有100个batch。每取完100个batch(不重复),就叫做跑完了一个Epoch。一个Epoch就意味着全部的样本都在网络中进行了一遍计算。
通过文件名队列,可以完成对Epoch更好的管理。比如在文件名队列中构造出3个Epoch,用A,B,C表示,那么它们都是包含了所有的文件列表的,那么就可以方便进行shuffle。



Cifar10数据解析编程案例
接下来以Cifar-10为例,介绍如何使用tf进行数据读取&数据打包。
Cifar-10也是图像分类任务,在卷积神经网中,我们评价一个模型效果的好坏,可以使用ImageNet数据集对模型进行性能评估,也可以使用Cifar-10或Cifar-100。
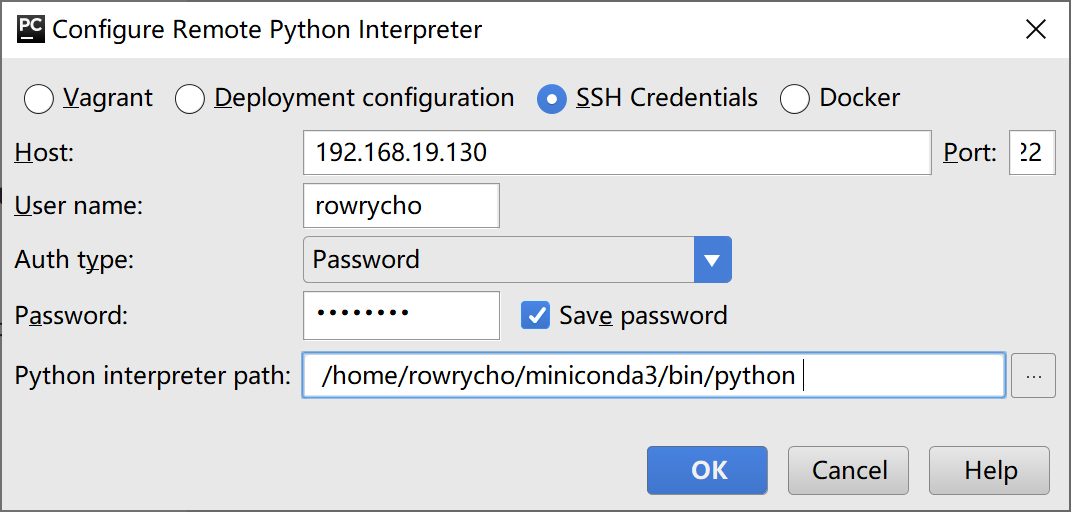
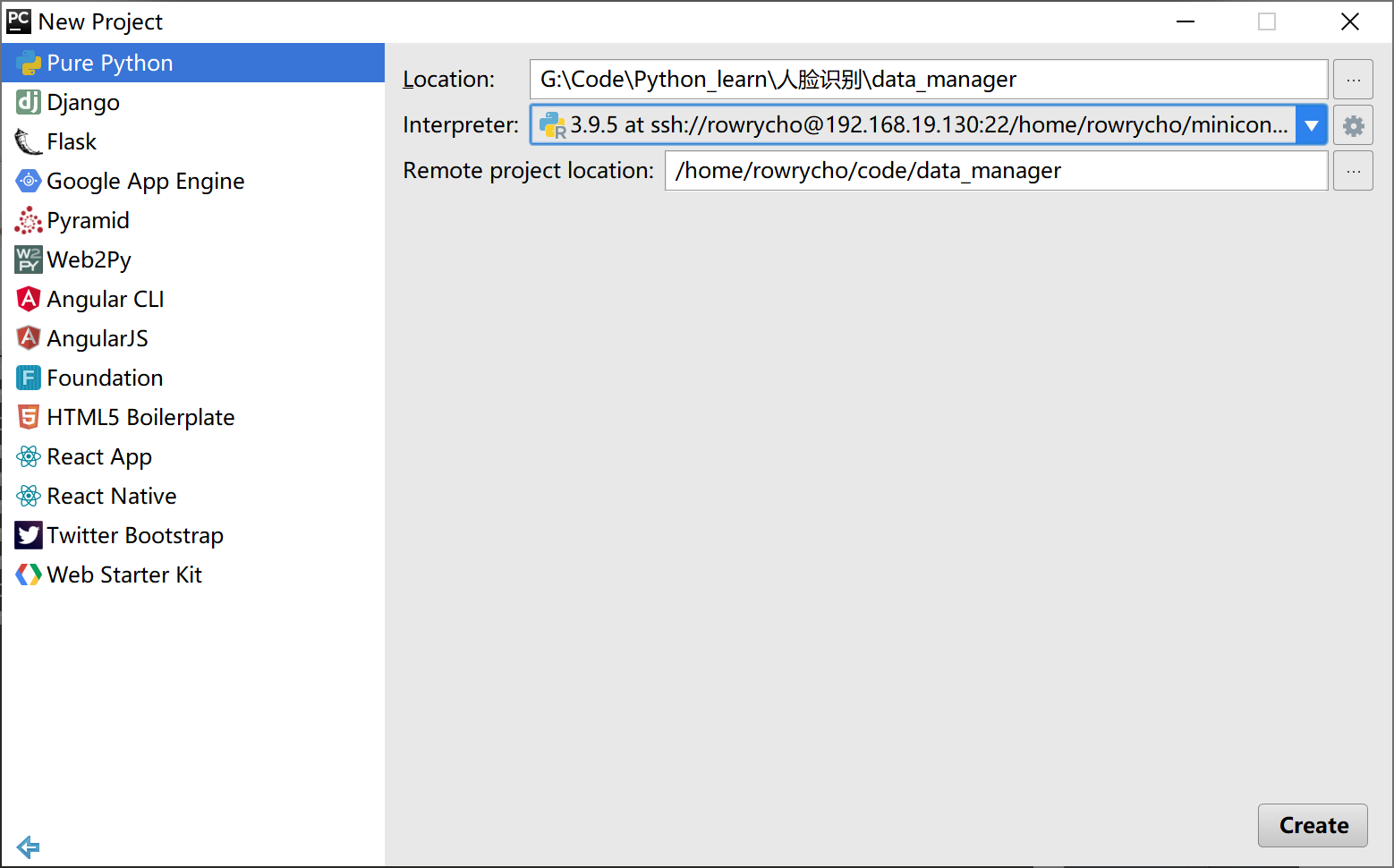
按照如下设置,本地连接远程编程环境!
cifar10数据集下载地址
http://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz
下载好cifar10数据,解压后,发现其是二进制格式存放的,为了更方便的展示读写的效果,会对这些二进制文件进行解析,将其解析成具体的图片,并将其存放在data/image/的train/和test/下。
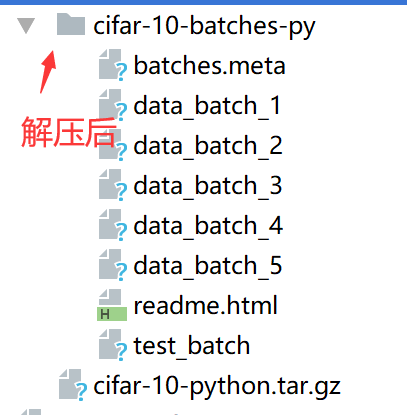
下面的代码是对cifar-10图片进行解码。
import urllib
import urllib.request
import os
import sys
import tarfile
import glob
import pickle
import numpy as np
import cv2 # pip install opencv-python
def download_and_uncompress_tarball(tarball_url, dataset_dir):
"""
完成对cifar10数据的下载和解压
Downloads the `tarball_url` and uncompresses it locally.
Args:
tarball_url: The URL of a tarball file.
dataset_dir: The directory where the temporary files are stored.
"""
filename = tarball_url.split('/')[-1]
filepath = os.path.join(dataset_dir, filename)
def _progress(count, block_size, total_size):
sys.stdout.write('>> Downloading %s %.1f%%' % (
filename, float(count * block_size) / float(total_size) * 100.0))
sys.stdout.flush()
filepath, _ = urllib.request.urlretrieve(tarball_url, filepath, _progress)
print()
statinfo = os.stat(filepath)
print('Successfully downloaded', filename, statinfo.st_size, 'bytes.')
tarfile.open(filepath, 'r:gz').extractall(dataset_dir)
DATA_URL = 'http://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz' # cifar10数据集
DATA_DIR = 'data'
# cifar10的10个分类
classification = ['airplane',
'automobile',
'bird',
'cat',
'deer',
'dog',
'frog',
'horse',
'ship',
'truck']
def unpickle(file):
"""
这是cifar10网站给的关于文件解析的脚本
:param file: 二进制文件
:return: 解析好的键值对
"""
import pickle
with open(file, 'rb') as fo:
dict = pickle.load(fo, encoding='bytes')
return dict
def to_image(from_file, to_file):
"""
将cifar10还原成图片
保存至 to_file/train/ to_file/test/
:param from_file: 图片二进制文件
:param to_file: 图片保存路径
:return:
"""
# 下面将二进制文件解析成图片
folders = from_file
# glob模块的主要方法就是glob,该方法返回所有匹配的文件路径列表(list)
# train_test_file = ["/data_batch*", "/test_batch*"]
for x in ["train", "test"]:
if x == "train":
t_files = glob.glob(folders + "/data_batch*")
else:
t_files = glob.glob(folders + "/test_batch*")
# 定义数据和标签为一个空格list
data = []
labels = []
# 将每个文件都进行解码,得到解码后的数据
for file in t_files:
dt = unpickle(file)
data += list(dt[b"data"])
labels += list(dt[b"labels"])
print(labels) # 打印标签 进行查看
# 在cifar10是通道优先的
imgs = np.reshape(data, [-1, 3, 32, 32])
for i in range(imgs.shape[0]): # imgs.shape[0] 图片数据总量
im_data = imgs[i, ...] # 获取第i张图片
im_data = np.transpose(im_data, [1, 2, 0]) # 将channel交换到最后一维
im_data = cv2.cvtColor(im_data, cv2.COLOR_RGB2BGR) # 将RGB转换为BGR模式
f = "{}/{}/{}".format("data/image", x, classification[labels[i]])
print(f)
if not os.path.exists(f):
os.makedirs(f)
# 命名 编号.jpg
cv2.imwrite("{}/{}.jpg".format(f, str(i)), im_data)
print("Finish!")
if __name__ == '__main__':
# 下载和解压cifar10数据
# download_and_uncompress_tarball(DATA_URL, DATA_DIR)
to_image("data/cifar-10-batches-py", "data/image/")
Tensorflow中TFRecord数据打包编程案例
然后需要对解码好的图片进行打包,生成TFRecord Writer。
import tensorflow as tf
import cv2
import numpy as np
import glob
import os
import warnings
from tqdm import tqdm
warnings.filterwarnings("ignore")
classification = ['airplane',
'automobile',
'bird',
'cat',
'deer',
'dog',
'frog',
'horse',
'ship',
'truck']
if __name__ == "__main__":
for x in ["test", "train"]:
idx = 0
im_data = []
im_labels = []
for path in classification:
path = "data/image/%s/" % x + path
im_list = glob.glob(path + "/*")
im_label = [idx for i in range(im_list.__len__())]
idx += 1
im_data += im_list
im_labels += im_label
print(im_labels[:10])
print(im_data[:10])
tfrecord_file = "data/%s.tfrecord" % x
with tf.python_io.TFRecordWriter(tfrecord_file) as writer:
# 使用shuffle进行打乱
index = [i for i in range(im_data.__len__())]
np.random.shuffle(index)
for i in tqdm(range(im_data.__len__())):
im_d = im_data[index[i]]
im_l = im_labels[index[i]]
data = cv2.imread(im_d) # 使用opencv读取图片
# 下面是另一种图片读取方式
#data = tf.gfile.FastGFile(im_d, "rb").read()
# 使用tf.train.Example将features编码数据封装成特定的PB协议格式
ex = tf.train.Example(
features=tf.train.Features(
feature={
"image": tf.train.Feature(
bytes_list=tf.train.BytesList(
value=[data.tobytes()])),
"label": tf.train.Feature(
int64_list=tf.train.Int64List(
value=[im_l])),
}
)
)
# 将example数据系列化为字符串,并将系列化为字符串的example数据写入协议缓冲区
writer.write(ex.SerializeToString())
如何使用tf.train.slice_input_producer读取文件列表中的样本
从文件列表中读取样本。
import tensorflow as tf
images = ['image1.jpg', 'image2.jpg', 'image3.jpg', 'image4.jpg']
labels = [1, 2, 3, 4]
"""
tf.train.slice_input_producer是一个tensor生成器,作用是按照设定,每次从一个tensor列表中按顺序或者随机抽取出一个tensor放入文件名队列。
"""
[images, labels] = tf.train.slice_input_producer([images, labels],num_epochs=None,shuffle=True)
with tf.Session() as sess:
sess.run(tf.local_variables_initializer())
tf.train.start_queue_runners(sess=sess)
for i in range(10):
print(sess.run([images, labels]))

如何使用tf.train.string_input_producer读取文件列表中的样本
从文件数据中读取样本。
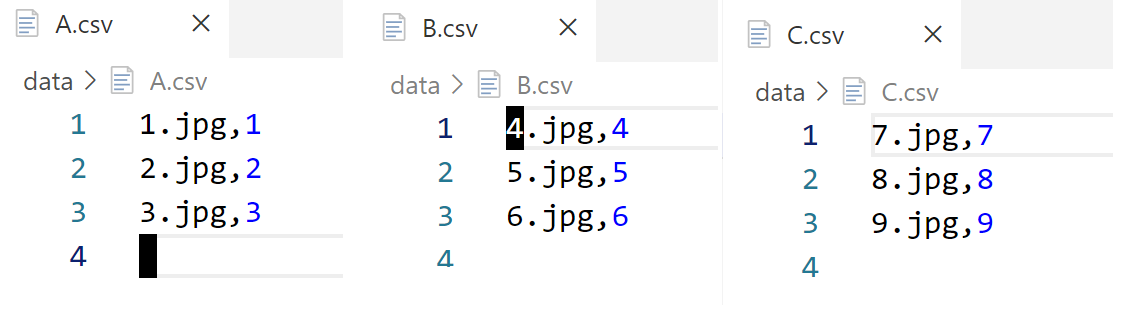
import tensorflow as tf
filename = ['data/A.csv', 'data/B.csv', 'data/C.csv']
file_queue = tf.train.string_input_producer(filename,
shuffle=True,
num_epochs=None)
reader = tf.WholeFileReader()
key, value = reader.read(file_queue)
with tf.Session() as sess:
sess.run(tf.local_variables_initializer())
tf.train.start_queue_runners(sess=sess)
for i in range(10):
print(sess.run([key, value]))
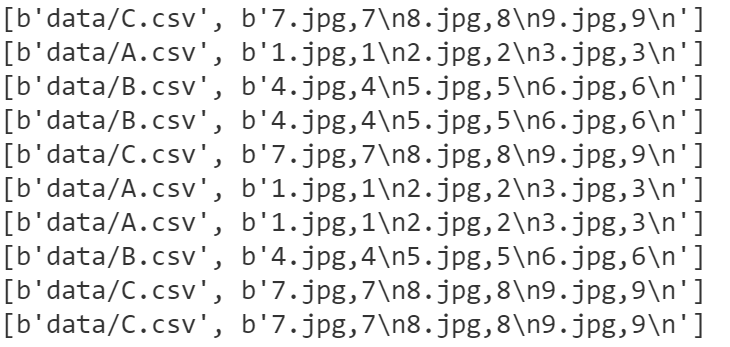
train.slice_input_producer 和 train.string_input_producer 的差别
主要的区别就是string_input_producer输出的结果是一个队列,而slice_input_producer输出的结果是一个tensor。后者可以直接用sess.run()的方式获得tensor的值,但是对于string_input_producer 没有办法这样直接获取。
如何通过TF对已经打包过的数据进行解析
import tensorflow as tf
import cv2
filelist = ['data/train.tfrecord']
file_queue = tf.train.string_input_producer(filelist,
num_epochs=None,
shuffle=True)
reader = tf.TFRecordReader()
_, ex = reader.read(file_queue) # 解码得到打包的数据
# 定义好feature
feature = {
'image': tf.FixedLenFeature([], tf.string),
'label': tf.FixedLenFeature([], tf.int64)
}
batchsize = 2
batch = tf.train.shuffle_batch([ex], batchsize, capacity=batchsize*10,
min_after_dequeue=batchsize*5)
example = tf.parse_example(batch, features=feature)
image = example['image']
label = example['label']
image = tf.decode_raw(image, tf.uint8)
image = tf.reshape(image, [-1, 32, 32, 3])
with tf.Session() as sess:
sess.run(tf.local_variables_initializer())
tf.train.start_queue_runners(sess=sess)
for i in range(1):
image_bth, _ = sess.run([image, label])
cv2.imshow("image", image_bth[0, ...])
cv2.waitKey(0)
上面的示例代码完成了对TFRecord数据的读取,并且每次读取的时候都是读取了一个batch_size的数据,也进行了可视化。
在进行模型训练的时候,就是这样,每次读取一个batch_size的数据,并且将这个batch_size的数据喂给网络训练。
TF中的高级API接口
之前介绍的是一些tf的基本api接口,如果我们在设计网路的时候,使用这些基本的api接口,这时候就需要写大量的代码。
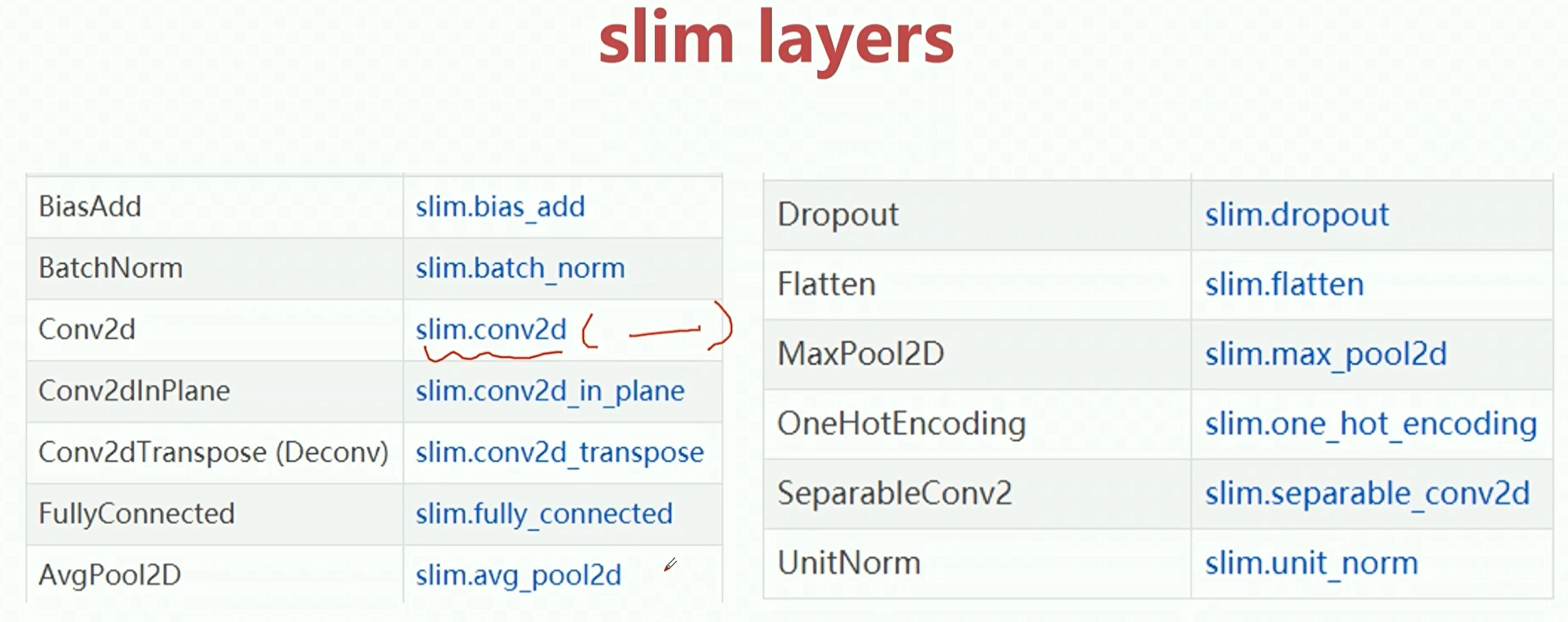
在tf中,有更加高层的封装,其中用的最多的就是slim和keras。















TF中的数据增强

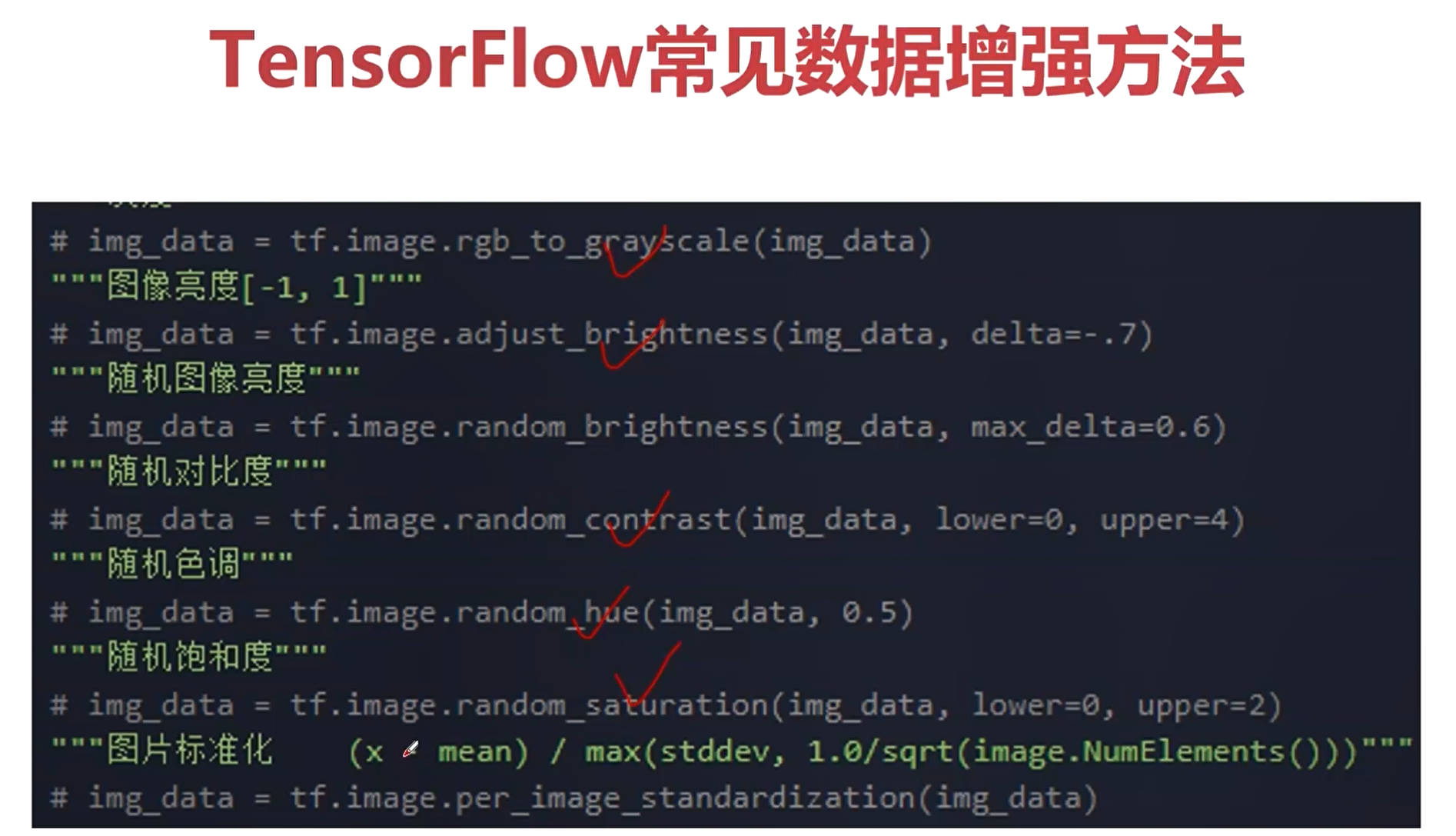
数据增强是防止过拟合非常常见的一个手段,在tf中可以通过 tf.image来对图像进行数据增强。
对图像数据进行扰动,进而提高模型对噪声的鲁棒性。

第一幅图是原图,后面的都是经过数据增强之后获取到的图像,这时候就相当于是产生了一些新的样本,而深度学习是要依赖于大数据的,数据越充分,那么学到的模型就更加的鲁棒。因此在进行模型训练的时候,数据增强是必须要使用的一种手段。
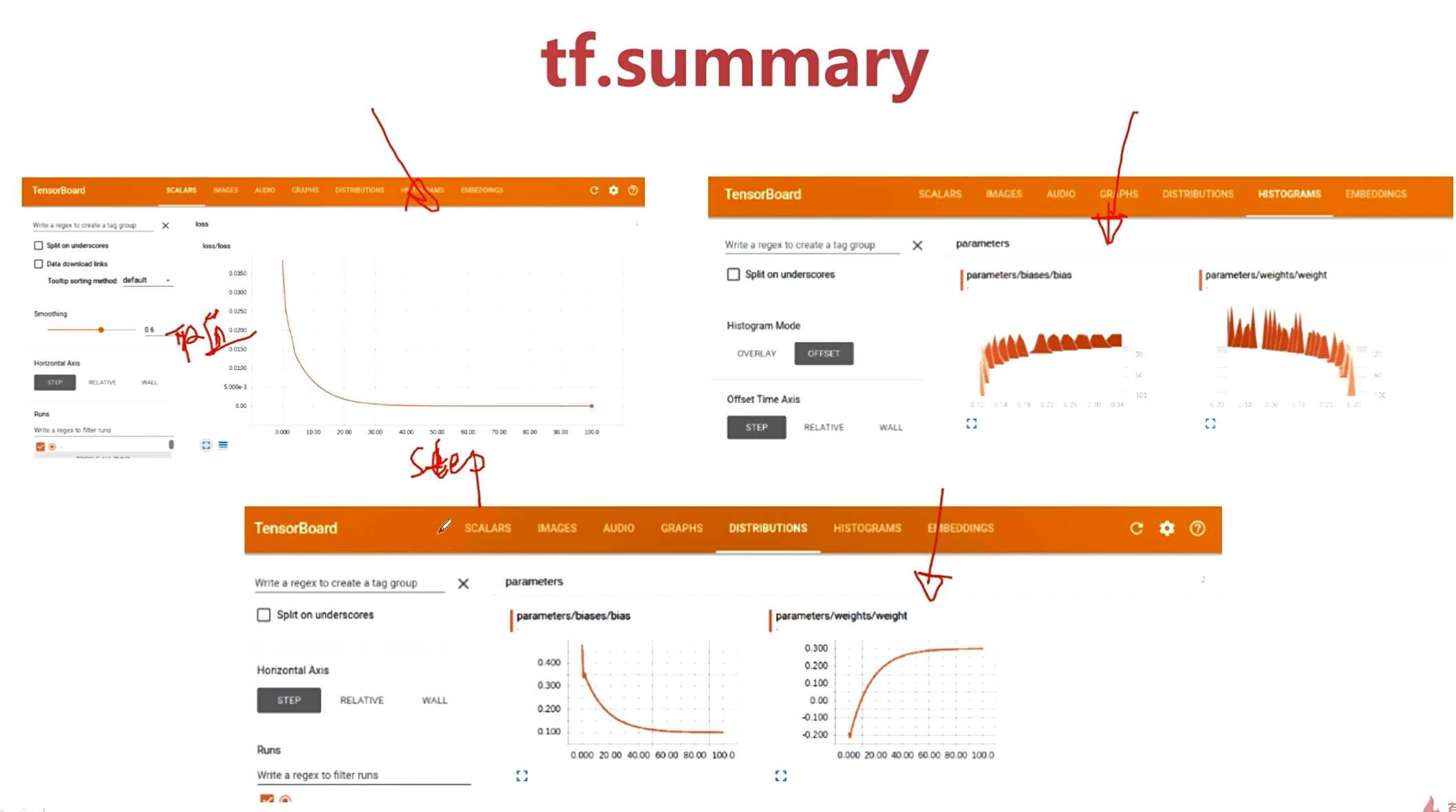
Tensorboard 调试技巧

Tensorboard:可以进行网络可视化/训练中间结果可视化。
训练中间结果采用sess.run()打印出来,或可以添加到tensorboard中,进行可视化展示。

小结
Tensorflow是什么?
TensorFlow:Google开源的基于数据流图的科学计算库,适用于机器学习、深度学习等人工智能领域。
TensorFlow的源码是开源的,可以在github上进行下载。
安装可以直接通过pip直接安装,也可以把源码下载到本地自己进行编译。
**然后TF中提供了很多模型,包括计算机视觉和自然语言处理的,在搭建模型的时候可以直接调用这里面的model。**
TensorFlow的架构
* 前端:编程模型、构造计算图、Python、Cpp、Java
网络也被称为计算图。
通过构造这样的一个图结构,并定好数据流向,来完成整个推理运算。
* 后端:运行计算图,C++
前端使用Python搭建网络模型,构造出来的计算图是不会运算的。前端搭建好计算图,并给定数据,后端再经过运算,得到输出。
Graph
Graph:描述了整个计算过程。
* 声明(单个/多个)
一个图表示一个网络,如果需要用到多个网络来解决一个任务,那就需要声明多个图,也就是多个Graph。
* 保存为pb文件
pb文件包括了网络的结构和网络的参数。
* 从pb中恢复Graph
* Tensorboard可视化
Graph是在前端来完成的,并且可以通过tf进行可视化展示。
上图是一个图形化的结果。
Session
Session
* Graph必须在Session的上下文中执行
* Session将Graph的op分发到诸如CPU或GPU之类的设备上运行
Graph <=> Session <=> 后端
Session相当于是Graph和后端的一个沟通的桥梁。
注入机制: 实际上就是Session具体完成计算图的过程,也是在注入机制中完成了前端和后端这个桥梁的作用。
Tensor
Tensor
* 在tf中,所有在节点之间传递的数据都为Tensor对象
* N维数组,图像:$(batch*height*width*channel)$
上图是tensor常用的定义方式,重点掌握前三种。
tf.constant() # 常量
tf.Variable() # 变量
tr.placeholder() # 占位符
Operation
Operation(op)
* tf Graph中的**计算节点**,输入输出均为Tensor
* 调用Session.run(tensor)或者tensor.eval()方可获取该Tensor的值
上图中的两个add,一个maltiply都是op。
具体计算图的op(操作)在哪里完成,可以通过Session来指定完成这些op的设备资源。
Feed & Fetch
Feed:通过feed为计算图注入值
Feed为Tensor完成具体值的注入,这里注入的值通常是那些占位符。
占位符是在构造计算图时,那些没有办法确定的Tensor。
Fetch: 使用Fetch获取计算结果
TFRecord
TFRecord: tf提供了TFRcord的格式来统一存储数据
TFRecord将图像数据和标签放在一起的二进制文件(protocol buffer),能更好的利用内存,实现快速的复制、移动、读取、存储。
tf的数据读取机制
输入数据 -> 文件名队列 -> 内存队列 -> 计算
文件名队列有什么用呢?这里就涉及到我们模型训练的一个概念——Epoch。
训练样本是分为一个一个batch的,意思就是每次从训练样本中取出一部分样本,用这个一部分样本来对网络参数进行调整,进行模型的训练。
假如训练样本有10000个,batch的数量为100,那么一个Epoch就有100个batch。每取完100个batch(不重复),就叫做跑完了一个Epoch。一个Epoch就意味着全部的样本都在网络中进行了一遍计算。
通过文件名队列,可以完成对Epoch更好的管理。比如在文件名队列中构造出3个Epoch,用A,B,C表示,那么它们都是包含了所有的文件列表的,那么就可以方便进行shuffle。
关于TFRecord的Writer和Reader
这是一个模板代码的..
知道这个东西,然后用的时候在对照着进行修改!
train.slice_input_producer 和 train.string_input_producer 的差别
主要的区别就是string_input_producer输出的结果是一个队列,而slice_input_producer输出的结果是一个tensor。后者可以直接用sess.run()的方式获得tensor的值,但是对于string_input_producer 没有办法这样直接获取。
tf的高层接口
之前介绍的是一些tf的基本api接口,如果我们在设计网路的时候,使用这些基本的api接口,这时候就需要写大量的代码。
在tf中,有更加高层的封装,其中用的最多的就是slim和keras。
数据增强
数据增强是防止过拟合非常常见的一个手段,在tf中可以通过 tf.image来对图像进行数据增强。
对图像数据进行扰动,进而提高模型对噪声的鲁棒性。
第一幅图是原图,后面的都是经过数据增强之后获取到的图像,这时候就相当于是产生了一些新的样本,而深度学习是要依赖于大数据的,数据越充分,那么学到的模型就更加的鲁棒。**因此在进行模型训练的时候,数据增强是必须要使用的一种手段。**