ABSTRACT
文章认为,现在的推荐系统使用的数据集大多都是隐式反馈的。虽然隐式反馈的数据集缓解了数据稀疏的问题,但存在一个缺点,反应用户实际满意度方面不够纯粹。例如,在电子商务中,很大一部分电极不会转化为购买,许多购买以负面评论告终。因此,去除隐式反馈中的噪声数据是至关重要的。
文章的目标是识别和修剪噪声交互,从而提高数据集的质量。文章通过对正常推荐其训练过程的观察,发现噪声数据在早期阶段通常由较大的损失值。受此启发,文章提出了一种新的训练策略,称为自适应去噪训练(Adaptive Denoising Training, ADT),能够自适应地修剪训练过程中的噪声交互。具体地,文章设计了两种自适应损失公式:截断损失,在每次迭代中以动态阈值丢弃大损失样本;重加权损失,自适应地降低大损失样本的权重。
INTRODUCTION
下表提供了关于false-positive交互负面影响的经验性证据:
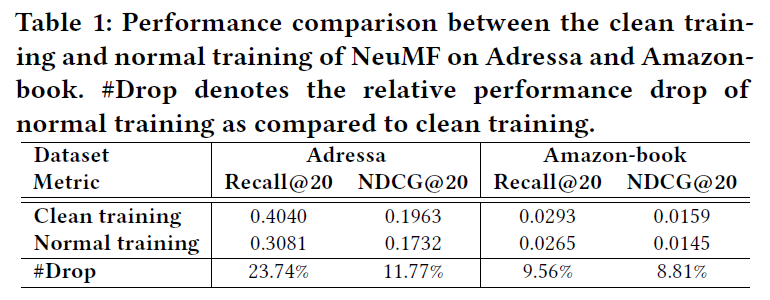
通过去除假阳性交互来构建一个”clean”的测试集。可以看出,用假阳性交互(正常训练)训练NeuMF会导致平均性能下降。因此,去除隐式反馈中的噪声是至关重要的。
一些研究通过如下方法来消除假阳性交互作用的影响:
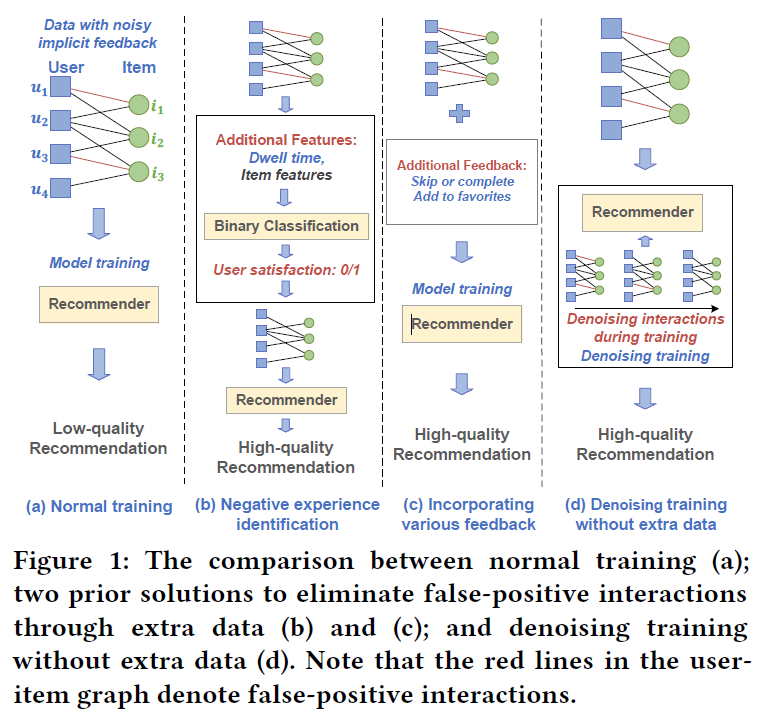
- 1)负面经验识别,Figure 1(b)。可以通过附加的用户行为(例如,停留时间和凝视模式)和辅助的项目特征(例如,项目描述)
- 2)纳入各种反馈来消除,Figure 1(c)。将额外的反馈(例如,喜爱和跳过)合并到推荐器训练中,以剔除假阳性交互的影响。
这些方法的限制是需要额外的数据,不容易手机。此外,额外的反馈规模较小,可能会受到稀疏性问题的影响。
文章提出了自动减少假阳性交互的影响,不适用额外的数据,Figure 1(d)
下图展示了上述方法:
观察在不同数据集上的不同推荐器的正常训练过程(如下图),调查了假阳性交互的属性及其对推荐器的影响:
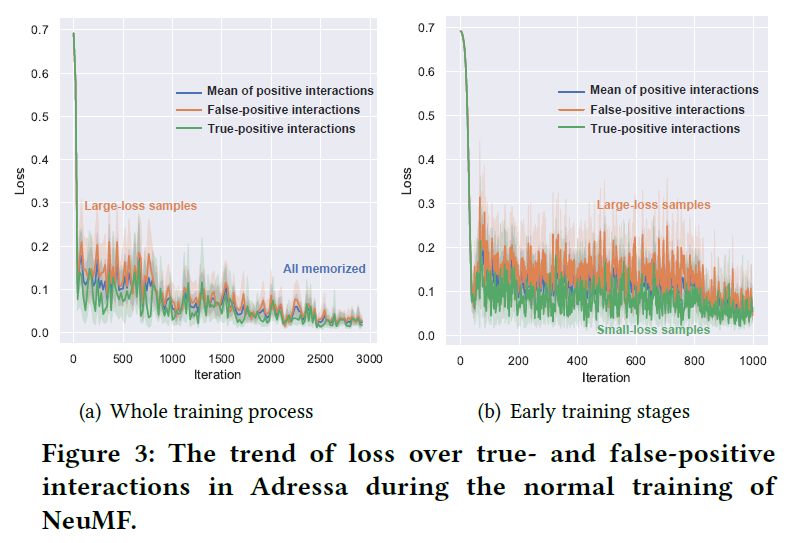
可以观察到:在训练的早期阶段,假阳性交互的损失值大于真阳性交互的损失值,而在训练结束时,两者的损失值下降到相同范围。结果表明:
- 假阳性互动更难适用于推荐器,在很大程度上会误导早期的培训目标。原因之一是假阳性交互代表用户不喜欢的项目,应该属于阴性样本;
- 推荐器由于其高表达性,最终能适合假阳性交互,这是过度拟合。
为了减少假阳性交互的影响,提出了一种自适应地修剪训练过程中损失值较大的交互。为了避免是去概括性,文章只修改了损失的表达方式。设计了两种范例来描述训练损失:
- 截断损失:通过动态阈值,来忽略大损失样本,这个阈值会动态更新;
- 重加权损失:动态分配较小权重给”harder”的交互,以削弱它们对模型优化的影响;
STUDY ON FALSE-POSITIVE FEEDBACK
数据集介绍:
- Adressa:这是一个新闻阅读数据集,其中包含用户点击新闻文章的停留时间。基于前人的经验,将停留时间小于10秒的点击识别为假阳性交互
- Amazon-book:这是一个产品推荐数据集,其中包含的购买历史评分范围从1到5(5表示最好),直观的将评分低于3的用户-商品交互视为假阳性交互
Settings:
在两种不同环境下训练一个推荐模型NeuMF
- “clean training”,它只在真阳性交互的数据集上训练NeuMF;
- “normal training”,在整体的数据集上训练NeuMF;
使用Recall@20和NDCG@20来评估。
Results:
上述的表1展示了结果,显示了假阳性交互的负面影响。尽管实验数据集上的clean training取得了成功,但是由于评分等可靠反馈的稀疏性,在实际应用中,并不是一个合理的选择。
METHOD
3.1 Task Formulation
学习一个函数(hat{y}_{ui}=f(u,i|Theta))来评估用户u对项目i的喜爱程度。
给定(mathcal{D}^*={(u,i,y_{ui}^*)|uin mathcal{U},iin mathcal{I}}),通过最小化损失函数
]
来学习推荐系统的参数(Theta ^*)
(y_{ui}^*in {0,1})表示用户u是真实的喜欢项目i。带有(Theta^*)参数的推荐系统能够可靠地产生高质量推荐。实际上,由于缺乏大量可靠的反馈,推荐系统的训练杯形式化成
]
其中(ar{mathcal{D}}={(u,i,ar{y}_{ui})|uin mathcal{U},iin mathcal{I}})是一个隐式交互的集合。(ar{y}_{ui})表示用户u和项目i之间可观察到的隐式交互;
可是,由于噪声隐式交互的存在,会误导用户偏好的学习。典型的推荐系统训练会形成一个缺乏泛化能力的较差的模型(对于clean testing set),因此制定了去噪推荐模型的训练任务如下:
]
目的是通过对隐式反馈进行去噪,学习一个可靠地参数(Theta^*)的推荐模型。形式上,假设(y_{ui}^*)和(ar{y}_{ui})存在不一致,将噪声隐式反馈定义为({(u,i)|y_{ui}^*=0land ar{y}_{ui}=1})。根据(y_{ui}^*)和(ar{y}_{ui})的值,将隐式反馈分为四类,如图所示:
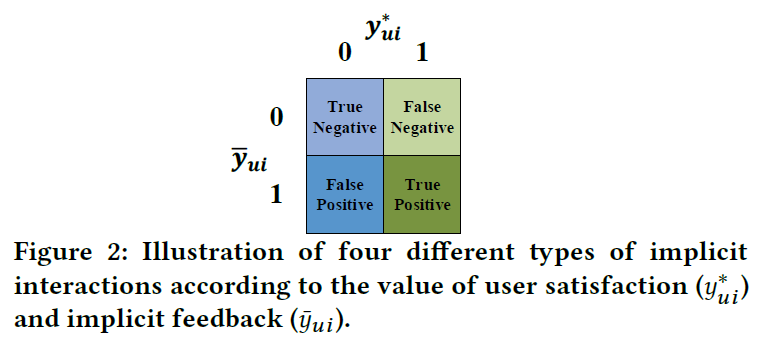
文章的目的是,去除假阳性交互,删除假阴性交互。在此项工作中,在训练过程中,没有使用显式反馈或者可靠地隐式反馈,来去除噪声数据。
3.2 Observations
图中可以观察到:
- 真阳性和假阳性交互的损失都会收敛到具有接近值的稳定状态,这说明NeuMF适合模拟这两个状态。同时也反映了深度学习的模型的模拟能力很强大,可以同时模拟正确和错误的标签样本。因此,如果训练数据有噪声,会导致较差的泛化能力;
- 在训练过程的早期,真阳性和假阳性交互的损失值有不同程度的下降。可以看出假阳性交互的损失明显大于真阳性交互的损失。真阳性交互的损失较小,意味着相对比较容易模拟。而损失较大的假阳性会更难模拟,原因是假阳性表示了用户不喜欢的项目。
3.3 Adaptive Denoising Training
推荐模型的ADT策略,根据训练损失来估计(P(y_{ui}^*=0|ar{y}_{ui}=1,u,i)),为了减少假阳性交互,ADT在训练过程中,动态修剪大损失交互。实际上,ADT对损失值较大的交互进行丢弃或者重新加权,以降低其对结果的影响。设计了两种模式来制定去噪训练的损失函数:
- Truncated Loss(截断损失):利用动态阈值函数将大损失交互的损失值截断为0;
- Reweighted Loss(重新加权损失):在训练过程中自适应地给harder样本分配较小的权重;
这两个范例基于传统的推荐损失(eg,CE loss, square loss, BPR loss)来公式化损失函数,在这篇文章中,使用CE loss作为例子来阐述这两种范式;
3.3.1 Truncated Cross-Entropy Loss
功能上讲,Truncated Cross-Entropy loss(简写为T-CE,截断交叉熵损失)会丢弃较大CE损失的阳性交互。满足基本要求,定义如下:
0,&mathcal{L}_{CE}(u,i)> au land ar{y}_{ui}=1 \
mathcal{L}_{CE}(u,i), & otherwise,
end{cases}
]
其中( au)是预先定义的阈值。T-CE损失从推荐参数的优化中除去CE损失大于( au)的所有正交互。这种简单的T-CE损失很容易解释和实现,但固定的阈值在整个训练过程中不能正常工作,这是因为损失值会随着训练迭代次数的增加而减小。为了适应训练损失的总体趋势,使用动态阈值函数( au(T))来代替固定的阈值( au)。此外,由于损失值在不同的数据集上有所不同,因此将其设计为drop rate(epsilon(T))的函数会更灵活。需要注意的是,drop rate和截断阈值之间存在双向映射。对于任何训练迭代,一旦drop rate给定,可以计算出阈值来过滤样本。
基于之前的观察,一个适合的drop rate函数需要有如下属性:
- (epsilon(cdot))应该有一个上限来限制丢弃样本的比例,以防止数据丢失;
- (epsilon(0)=0),允许所有样本在开始时输入模型;
- (epsilon(cdot))应该从0平滑地增加到上限,以便魔心可以逐渐学习和区分真假阳性交互;
因此,将drop rate函数定义如下:
]
其中,(epsilon_{max})是一个上界,(alpha)是一个超参数来调整达到最大drop rate的速度。在实验中,采用线性方式来增加drop rate,而不是使用复杂的函数,以防止更多的超参数。整个算法的解释如下:

3.3.2 Reweighted Cross-Entropy Loss
重加权交叉熵(简称R-CE),降低了具有大损失值的正交互作用的权重,定义如下:
]
其中,(omega(u,i))是一个权重函数,用于调整观察到的交互对训练目标的贡献。为了实现对大损失样本进行适当降权的目标,权重函数(omega(u,i))需要有如下特性:
- 该函数在训练期间动态调整样本的权重
- 该函数将harder样本(大损失交互的样本)的影响降低到比简单样本弱的程度;
- 权重减轻的程度可以简单的调整,以便可以适应不同的模型和数据集
由于Focal Loss的成功,文章用函数(f(hat{y}_{ui}))来估计(omega(u,i)),该函数把预测分数作为输入。预测分数和CE损失在用于识别harder样本是等效的。文章使用预测分数的原因是它值的范围是[0,1],而不是[0,+(infty)],对进一步的计算会更友好。定义如下:
]
其中(eta in [0,+infty])是一个超参数来控制权重的范围。
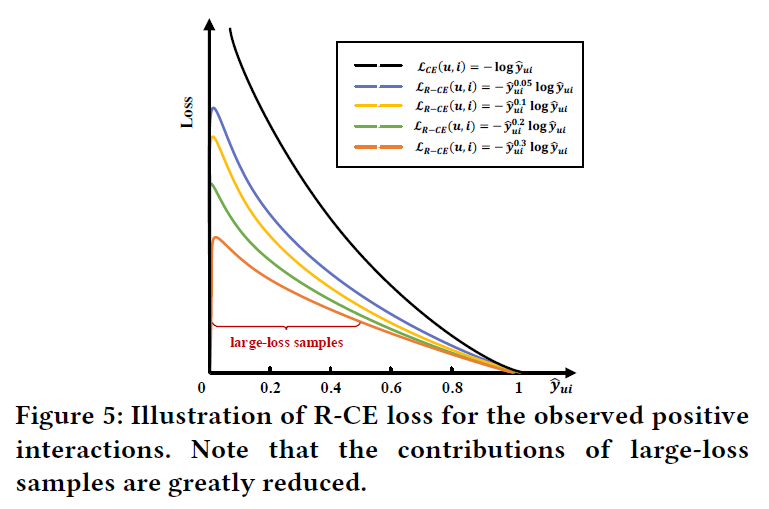
从上图可以看出,与原始CE损失相比,配备了所提出的权重函数的R-CE损失可以显著减少harder样本的损失,权重函数需要满足以下要求:
- (f(hat{y}_{ui})=hat{y}_{ui}^{eta})对于损失值相比(hat{y}_{ui})更加敏感。因此,它可以在训练过程中生成动态权重;
- 具有极大损失的交互(例如图6的“outlier”——异常值)将被分配非常小的权重,因为(hat{y}_{ui})接近于0。因此,大损失样本的影响大大降低。从下图可以看出,较难的样本总是具有较小的权重,不过困难样本和简单样本的权重都降低。这是因为当(hat{y}_{ui}in [0,1]),(eta in [0,+infty])函数(f(hat{y}_{ui})=hat{y}_{ui}^{eta})是单调递增的。harder样本的预测评分比easy样本的评分低。因此,可以避免具有大损失值的假阳性样本在优化过程中占主导作用。
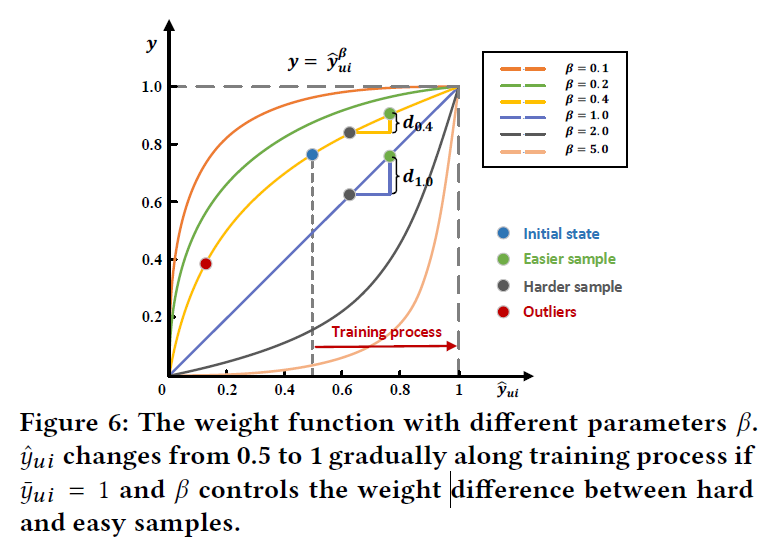
- 超参数(eta)在训练过程中,动态地控制困难交互和简单交互之间的gap,上图绘制了各种(eta)设置下的权重函数(f(hat{y}_{ui})=hat{y}_{ui}^{eta})。在训练过程中,预测分数(hat{y}_{ui})在初始迭代中波动在0.5左右,然后逐渐移动到1。在图6中,绘制了四种情况,initial states,easier sample,harder sample,outlier。从图中可以看出:
- 1)(hat{y}_{ui}^eta)是递增的
- 2)(eta)的增大,对于同一对简单和困难的样本,它们之间的权重差距会变得更大,如图中的(d_{0.4}<d_{1.0})。此外,如果将(eta)设置为0,R-CE损失退化成标准的CE损失。
在实验中,为了保证所有样本的损失值在同一范围内,防止损失值较大的负样本主导优化,在范式中也对负样本进行加权,于是得到如下的权重函数:
hat{y}_{ui}^eta, & ar{y}_{ui}=1\
(1-hat{y}_{ui})^eta,& otherwise
end{cases}
]
此外,在计算梯度以更新模型参数(Theta)时,权重函数中的(hat{y}_{ui}^eta)被视为一个常数。否则会误导优化方向。具体计算如下:
]
EXPERIMENT
Dataset
数据集的统计如下:
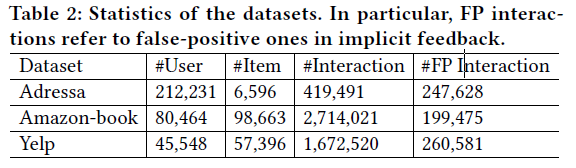
- Adressa:这是Adressavisen的真实新闻阅读数据集。它包括匿名用户和他们点击的新闻。此外,还记录了每次用户-项目交互的停留时间。基于已有的工作,驻留时间小于10秒的交互作用被认为是假阳性的;
- Amazon-book:此数据集包括用户对其购买的书的评分;
- Yelp:用户对餐饮业的评分,其中评分低于3分被视为假阳性反馈;
对于Adressa,由于新闻的时效性,按照8:1:1的比例将将用户-项目交互分为训练集、验证集和测试集。对于另外两个数据集,按照相同的比例随机拆分数据集。最终,删除测试集中的所有假阳性交互,以确保评估的可靠性。
Evaluation Protocols
对于测试集中的每个用户,实验预测除训练期间使用的正样本外的所有项目的偏好分数。用户从未发生交互的所有项目被视为负面项目。继现有研究,实验采用了两个指标:Recall@K和NDCG@K。因为Adressa的商品数量远小于Amazo-book和Yelp,默认的K是50和100,但是在Adressa上的K为3或20;
Testing Recommenders
实验为几个神经模型配置这两种范式,然后探索这些模型在干净的数据集上,是否实现了更好的泛化性能。选择的模型:GMF、NeuMF、CDAE。因为GMF和MeuMF是具有代表性的协同过滤方法,CDAE结合了随机噪声来减少噪声反馈的干扰;
- GMF:矩阵分解的广义版本,将内积替换为逐元素乘积和线性神经层作为交互函数;
- NeuMF:NeuMF是具有代表性的CF神经模型,它通过结合GMF和多层感知器(MLP)对用户和项目之间的关系进行建模;
- CDAE:用随机噪声破坏观察到的交互作用,然后采用MLP模型重建原始交互,部分提高了抗噪声能力;
在实验中,只对神经网络推荐模型进行测试,忽略了传统推荐模型,因为最近的工作验证了神经网络推荐模型相对于传统推荐模型的优势;
Parameter Settings
对于三个测试推荐模型,遵循它们默认的设置。
ADT策略有三个超参数:在T-CE loss中的(alpha,epsilon_{max}),在R-CE loss中的(eta)。(epsilon_{max})在{0.05, 0.1, …, 0.5}中搜索,(eta)在{0.05, 0.1, …, 0.25, 0.5, 1.0}中调整,控制(alpha)的范围,通过迭代次数(epsilon_N)调整到最大drop rate:(epsilon_{max})。(epsilon_N)在{1k, 5k, 10k, 20k, 30k}中选取;
5.1 Overall Performance
下表显示了三个数据集的结果,可以得到以下几点结论:
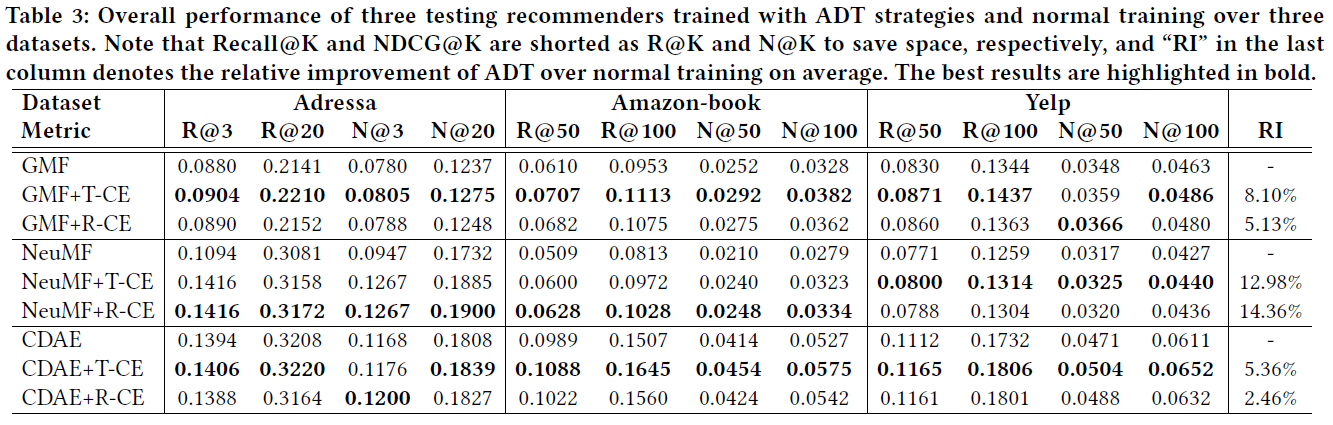
- 提出的ADT策略有效地提高了推荐模型在干净测试集上的性能。且两种范式的相对改进都是显著的。表明所提出的ADT策略成功地减少噪声隐式反馈的影响并增强了泛化能力;
- 通过比较T-CE和R-CE,可以看出T-CE的表现更好。这是因为R-CE仍然受到假阳性交互的影响,即使它们具有较小的权重。此外,T-CE中的动态阈值函数可以通过两个超参数进行更精确的调整;
- ADT在NeuMF上实现了最大的性能提升,而对GMF和CDAE的改进相对较小。比较正常训练的结果,可以发现NeuMF的表现比GMF和CDAE差,尤其是在Amazon-book和Yelp上,表明NeuMF更容易受到嘈杂交互的影响。原因可能是NeuMF中的MLP模型增加了复杂性,并使NeuMF适合更多的假阳性交互。ADT给NeuMF更大的性能提升,表明ADT可以有效地防止易受攻击的模型受到噪声数据的干扰;
- 对于三个数据集的差异,可以看到最大的性能改进是在Amazon-book上,而最小的是Adressa上。可能是因为Adressa的训练样本较少,更糟糕的是,Adressa的假阳性交互在所有观察到的阳性交互中占59%以上,这极大地影响了神经网络推荐模型的去噪训练。这意味着训练数据中很大比例的噪声交互部分限制了ADT的改进;
5.2 Discussion
5.2.1 Memorization of False-positive
实验也探索结合ADT策略的推荐模型是否能够很好地拟合假阳性交互。下图显示了Amazon-book上训练GMF过程中假阳性交互和所有训练样本的CE损失值的趋势:
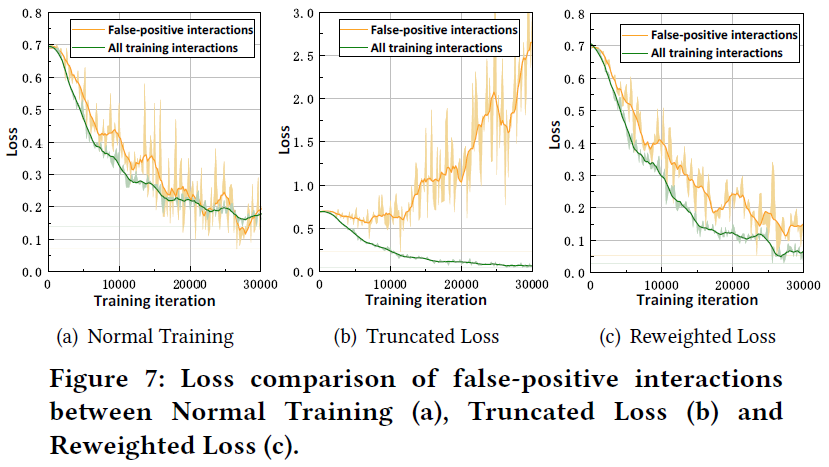
- 假阳性交互的损失值最终变得与其他样本相似,表明GMF最终能很好地记住假阳性样本;
- 当GMF用T-CE loss训练时,假阳性交互的损失值变得非常大,而所有训练样本的损失值都稳定且很小。这是因为推荐器总是选择损失小的样本来优化参数,越来越多的噪声交互在训练过程中没有拟合;
- 当使用R-CE损失训练GMF时,假阳性交互的损失也随着训练过程而减少。
上述观察中,可以得出结论,两种范式都减少了假阳性交互对推荐模型训练的影响。可以解释为什么他们能比正常训练实现了性能提升。
5.2.2 Study of Truncated Loss
由于截断损失在实验中取得了优异的性能,文章研究它在识别和丢弃假阳性交互方面的表现。定义Recall来表示训练数据中假阳性交互被丢弃的百分比,并将精度视为丢弃的假阳性交互与所有丢弃样本的比率。下图显示了在训练过程中召回率和准确率的变化。其中的绿线表示随机丢弃设置下的召回率和准确率。特别是,随机丢弃的召回率等于训练期间的丢弃率,而其精度是每次迭代时所有训练样本中噪声交互的比例。
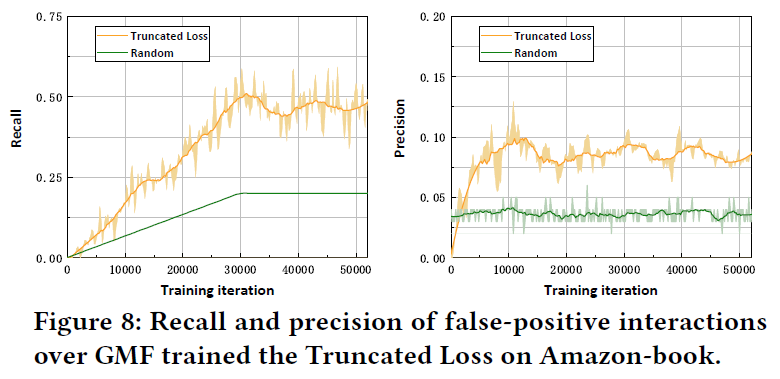
- 在drop rate稳定后,截断损失丢弃几乎一半的假阳性交互;大大地降低了噪声交互的影响;
- 截断损失的精度大约是随机丢弃精度的两倍。它表明截断损失有效地利用了假阳性交互的信号,并削弱了它们对模型训练的影响;
但是截断损失的局限性在于精度低,例如,图8只有10%的精度,这意味着它会丢弃许多干净的交互。这也部分证明了以丢弃许多干净样本为代价来修剪嘈杂的交互是值得的。
5.2.3 Hyper-parameter Sensitivity
下图展示了在Amazon-book和Yelp上使用ADT策略训练的GMF的结果:

从图中可以看出:
- 当(epsilon_{max}in [0.1, 0.3])时,使用T-CE损失训练的推荐模型实现了最大的性能提升。如果(epsilon_{max})超过0.4,性能会显著下降。因为丢弃了很大比例的样本。因此,截断损失的上限(epsilon_{max})应该受到限制;
- 推荐模型与(epsilon_{N})的关系更密切,尤其是在Amazon-book上,当(epsilon_{N})大于30k时了,性能仍然提高。但限制是大搜索空间限制了超参数调整;
- 重加权损失中的(eta)的调整在不同的数据集上是一致的,当(eta)的范围在0.15到0.3时,效果最好。
5.2.4 Performance Comparison w.r.t. Interaction Sparsity
由于稀疏性问题组织了推荐模型学习非活跃用户的偏好,继续研究ADT策略是否影响非活跃用户偏好的学习,因为在训练期间修剪了许多交互。根据每个用户的交互次数将测试用户分为四组。并且每个组总共有相同数量的交互,下图显示了不同组别GMF结果:
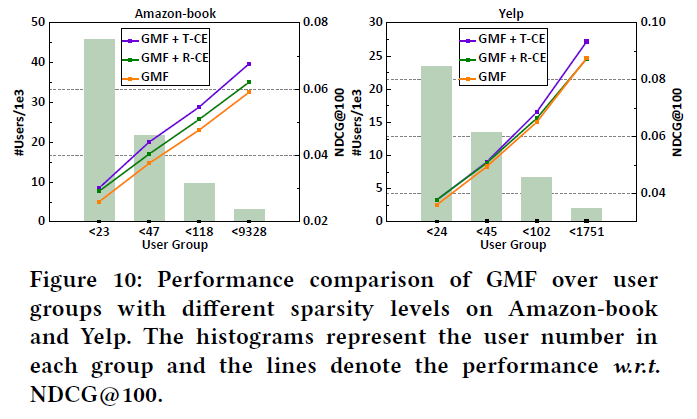
可以观察到,ADT策略提高了不同数据集上所有用户组的性能,表明ADT策略稳定且对不活跃的用户也有效;